Architecture Overview¶
这里我们会对xpaw的结构进行简要的介绍。
首先我们会给出爬虫运行过程中的数据流图,接着我们会对数据流中呈现的各个组件进行简要的介绍。
Data Flow¶
数据流以crawler为核心,并由crawler进行控制和驱动:
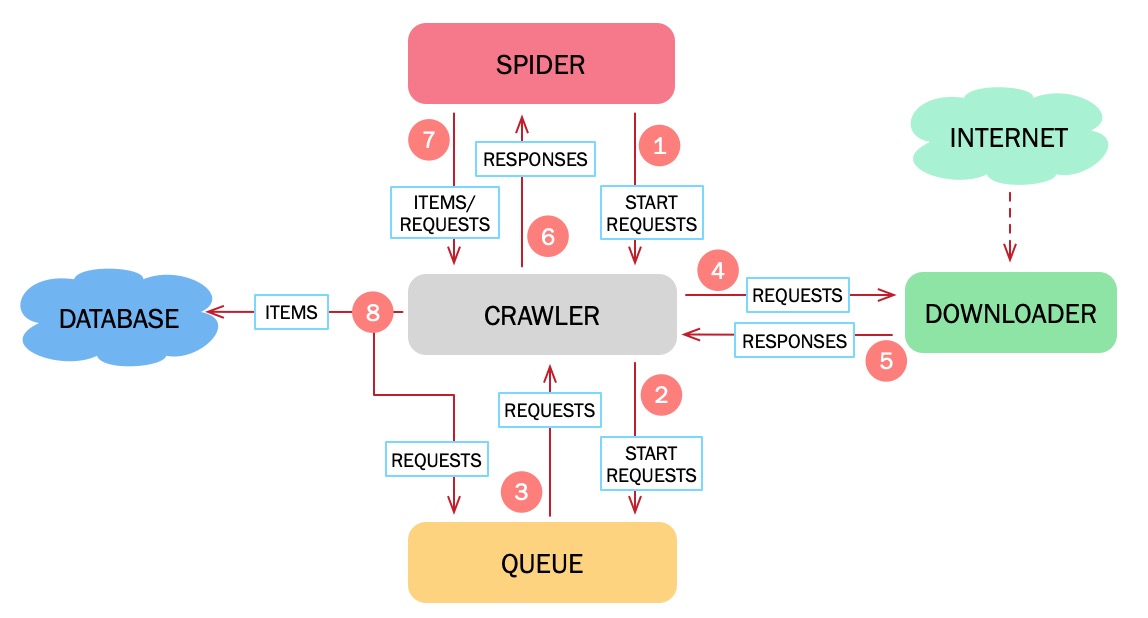
- crawler从spider中获取初始请求
HttpRequest。 - crawler将得到
HttpRequest放入到queue中。 - crawler不停地从queue中获取待处理的
HttpRequest。 - crawler将
HttpRequest交由downloader处理。 - downloader完成下载后生成
HttpResponse返回给crawler。 - crawler将得到的
HttpResponse交由spider处理。 - spider处理
HttpResponse并提取数据Item和新的请求HttpRequest。 - crawler将得到的
HttpRequest放入到queue中。
爬虫会持续运行直到所有生成的requests都被处理完且不再生成新的requests为止。
